
最近、XRやロボティクス界隈の情報を漁っていたところ、「これはちょっと、ゲームチェンジャーかもしれない」という論文とプロジェクトページを偶然発見しました。
NVIDIA Labsが公開した『Fast-FoundationStereo』という技術です。
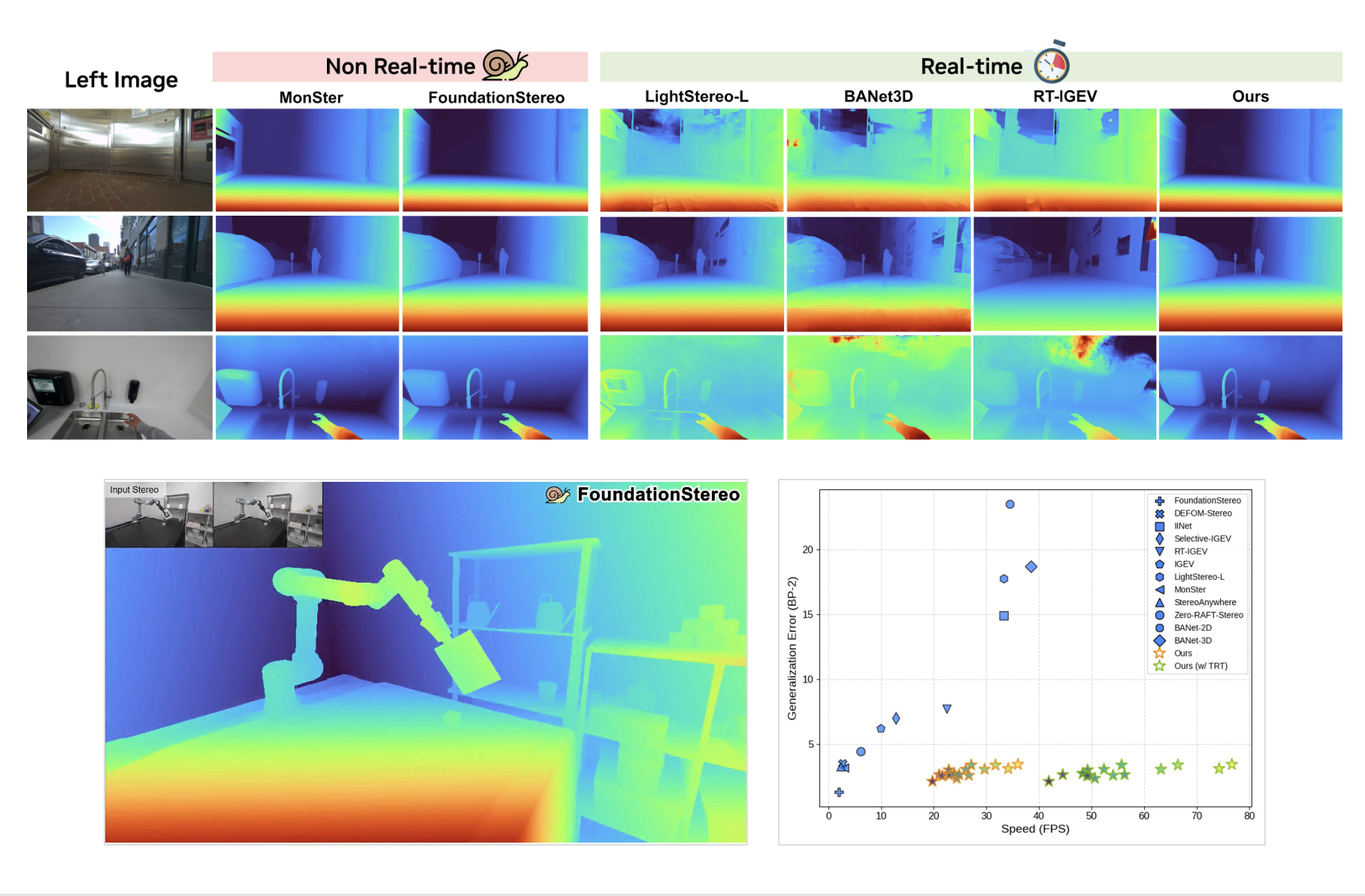
パッと見た感じ、「ステレオマッチング(2枚の画像から奥行きを測る技術)」の新しいモデルのようなのですが、デモ動画のヌルヌル具合と、謳っている精度の高さのギャップに驚きました。
「英語だし数式多そうだし…」とスルーするのはあまりに勿体無い内容だったので、このプロジェクトが何を解決しようとしていて、僕らのクリエイティブにどう影響するのか、自分なりに噛み砕いてまとめてみました。
開発者やXRクリエイターの方にとって、「未来の当たり前」を先取りする情報になれば嬉しいです。
Contents
そもそも、何がそんなに凄いの?
一言で言うと、「これまでトレードオフだった『速度』と『精度』の壁をぶち壊した」点に尽きます。
これまで、画像から奥行き(深度)を推定するAIには、大きく分けて2つの派閥がありました。
-
賢いけど、重い(Foundation Models)
-
どんな場所でも正確に距離がわかる。でも計算が遅すぎて、リアルタイムなアプリには使えない。
-
-
速いけど、融通が利かない(Efficient Models)
-
サクサク動く。でも、学習していない「初めて見る場所」に行くと、途端に精度がボロボロになる。
-
つまり、「リアルタイムで動かしたいなら、精度は妥協してね」「精度が欲しいなら、後処理で時間をかけてね」というのが、これまでの常識だったわけです。
ところが、今回発表された『Fast-FoundationStereo』は、この常識を覆しています。
"Strong zero-shot generalization at real-time frame rate" (リアルタイムなフレームレートで、強力なゼロショット汎化性能を実現)
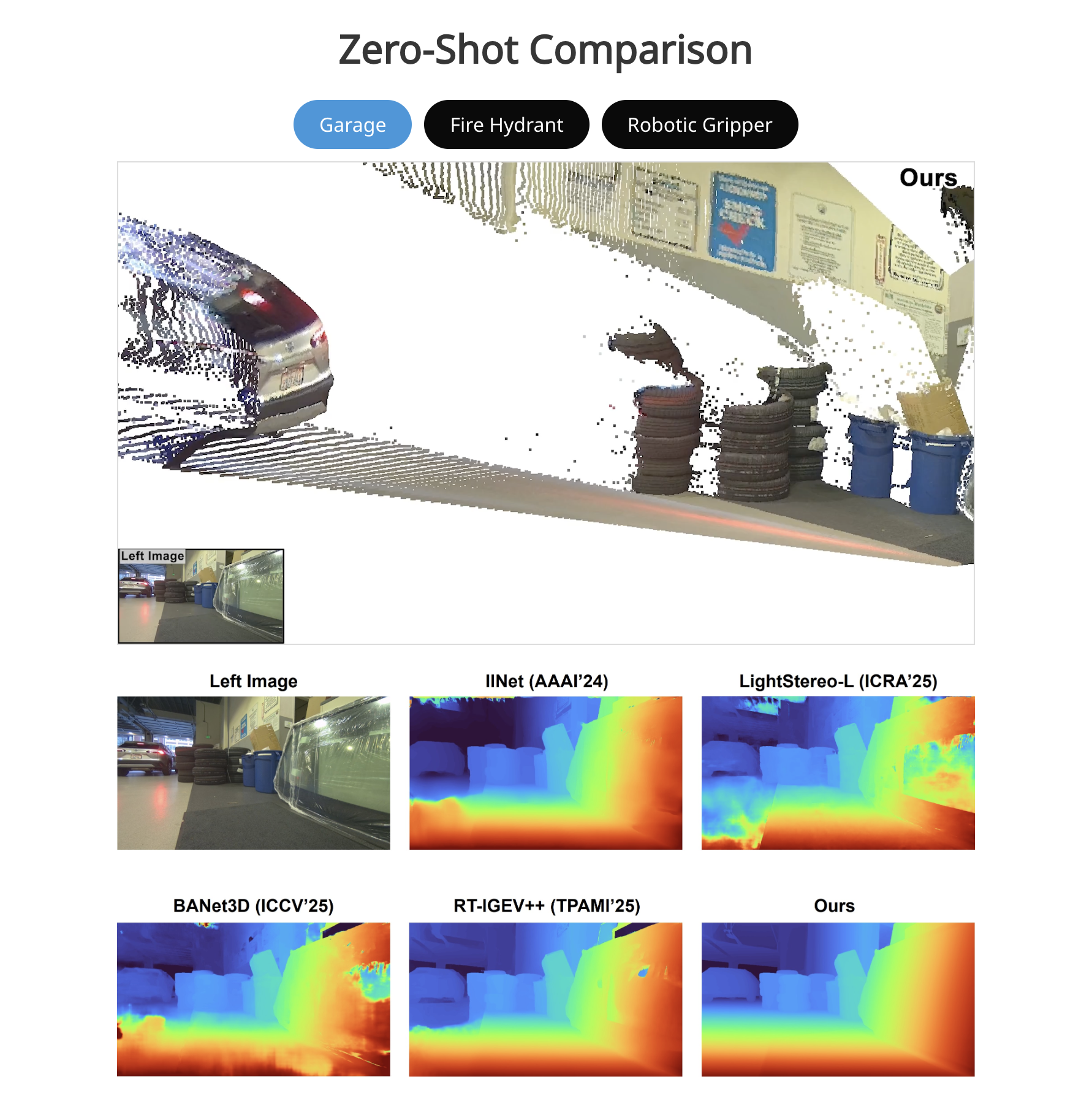
要するに、「初めて見る場所でも人間の目のように正確で、しかも爆速で動く」ということです。
数字で見る衝撃:既存最強モデルの「10倍」速い
プロジェクトページによると、これまでの最高峰モデル(FoundationStereo)と比較して、同等の精度を保ちながら10倍以上の処理速度を叩き出しているそうです。
これ、地味に聞こえるかもしれませんが、革命的です。 これまで「ハイスペックPCがないと無理」だった高度な空間認識が、近い将来、スマホやスタンドアローンVRヘッドセットのエッジ処理でサクサク動くようになる可能性を示唆しているからです。
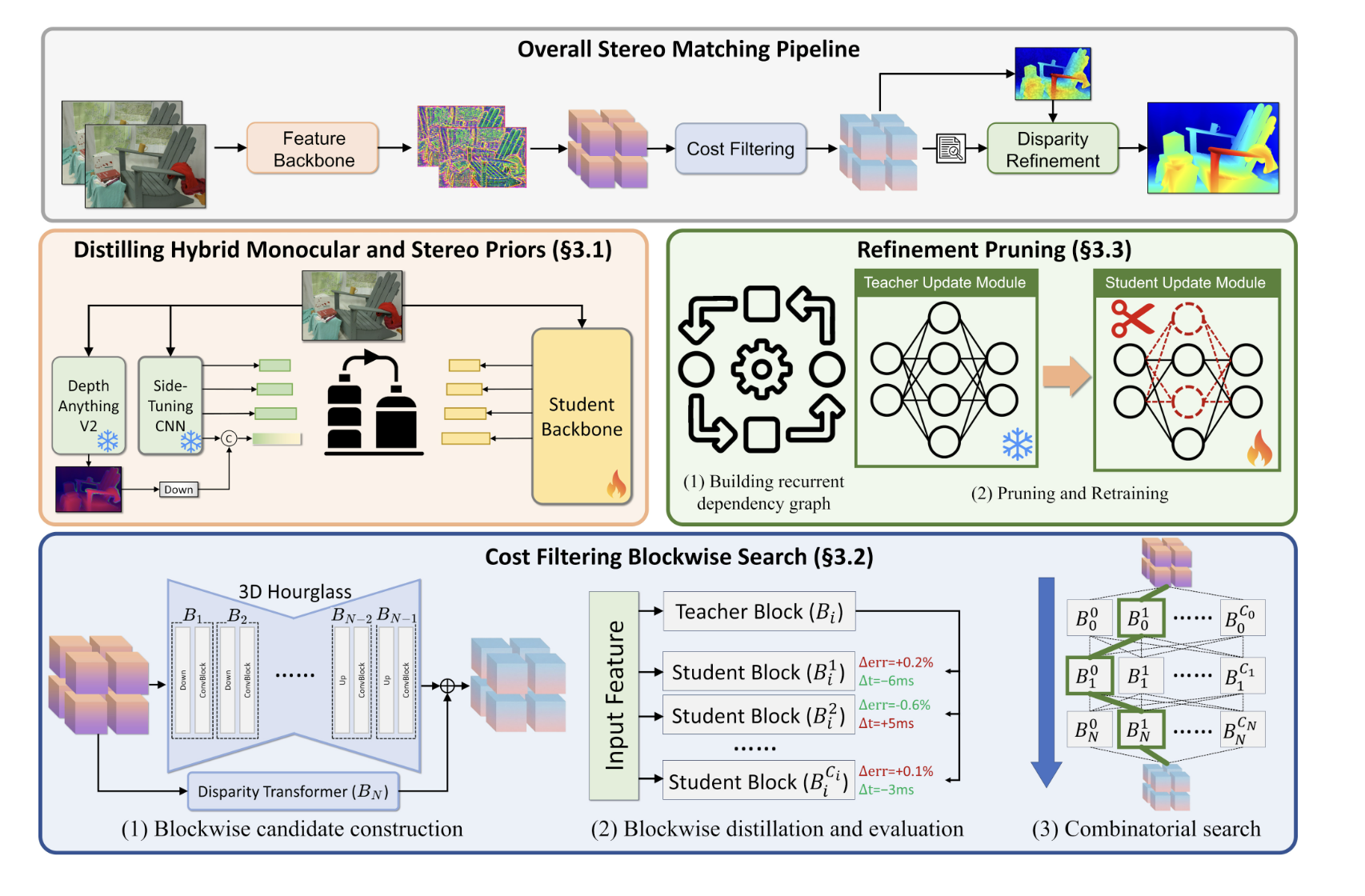
どうやって実現したの?(技術のキモ)
「そんな都合のいい話があるの?」と思って仕組みを読んでみたところ、NVIDIAらしい力技と賢い工夫が組み合わされていました。
1. 巨大な脳を、小さな脳に「蒸留」する
彼らは「Knowledge Distillation(知識の蒸留)」という手法を使っています。 まず、超賢くて重い「先生モデル」を用意します。そして、その先生の知識を、軽量な「生徒モデル」に徹底的に教え込ませるのです。これにより、生徒(軽量モデル)は、先生譲りの賢さを持ちながら、身軽に動けるようになります。
2. インターネット規模の画像を「教科書」にする
AIを賢くするにはデータが必要です。しかし、正確な「奥行きデータ」付きの画像を集めるのは大変です。 そこで彼らは、インターネット上の大量の画像データを使い、AI自身に「疑似ラベル(Pseudo-labeling)」を作らせて学習させました。その数なんと140万ペア。 研究室の綺麗なデータだけでなく、ノイズの多い「野生のデータ」で鍛え上げられたからこそ、どんな環境でも動くタフさを手に入れたようです。
僕たちの「体験」はどう変わる?
この技術、単なる研究発表で終わらせるには惜しいポテンシャルを持っています。もしこれが一般化すれば、UI/UXやコンテンツ制作の現場ではこんなことが起きそうです。
-
ARの「位置ズレ」が消滅する
-
ポケモンGOのようなARや、Apple Vision Proのようなパススルー映像で、CGが現実の家具にピタリと吸着し、手前に物が来たら遅延なく隠れる(オクルージョン)表現が、どんな部屋でも完璧に行えるようになります。
-
-
「スキャン待ち」のイライラがなくなる
-
空間認識系のアプリでよくある「スマホを振って床を認識させてください」という儀式。あれが不要になり、アプリを開いた瞬間に空間が認識されている、というUXが当たり前になるかもしれません。
-
-
ドローンやロボットが賢くなる
-
配送ロボットなどが、散らかった部屋や予測不能な屋外でも、ぶつからずにスイスイ動けるようになります。
-
まとめ:未来のUIは「待たせない」
Web制作やアプリ開発をしていると、つい「リッチな表現」と「パフォーマンス」のバランスに悩みますが、バックエンドのAI技術がここまで進化すると、フロントエンドの表現力もリミッターを外せそうです。
特に、「Zero-shot(事前学習なしで未知の環境に対応できる)」という点は、ユーザーに負担をかけないUIを作る上で非常に重要です。
ソースコードも公開予定とのことなので、エンジニアの方はぜひGithubを覗いてみてください。 僕もデモを触れるようになったら、実際に手元の映像で試してみたいと思います。
Reference: Fast-FoundationStereo: Real-Time Zero-Shot Stereo Matching

{kind=link}